Building a Self RAG System with LangGraph: Now with Hallucination Detection
Today, we will enter an exciting advance: Self RAG (Retrieval-Augmented Generation). It’s an implementation using LangGraph, moving us toward the systems in AI that self-reflect and self-improve.
What is Self RAG?
The traditional RAG (Retrieval-Augmented Generation) system is extended to create Self RAG. Wherein the language models are only enhanced to retrieve actual pieces of information from a knowledge base by RAG, Self RAG looks a bit beyond that. Self RAG demonstrates self-reflection mechanisms that allow the system to evaluate and also improve its generated outputs.
Key features of Self RAG include:
- Retrieved documents are self-assessed
- There will be multiple attempts to generate provided the initial results are not satisfactory.
- To retrieve additional information if needed
Components and Workflow
Our Self RAG architecture encompasses the following basic modules:
Retriever: Retrieves relevant documents based on the input question.
Document Grader: Grades the relevance of the retrieved documents
Web Search: Searches online when the local document supply is insufficient.
Generator: Generates a response based on the obtained information.
Generation Grader: Grades the generated response for hallucinations and relevance.
The workflow is defined using a StateGraph from LangGraph, allowing for complex, conditional paths through the system.
Code Breakdown
Let’s examine the key parts of our Self RAG implementation:
Graph Definition
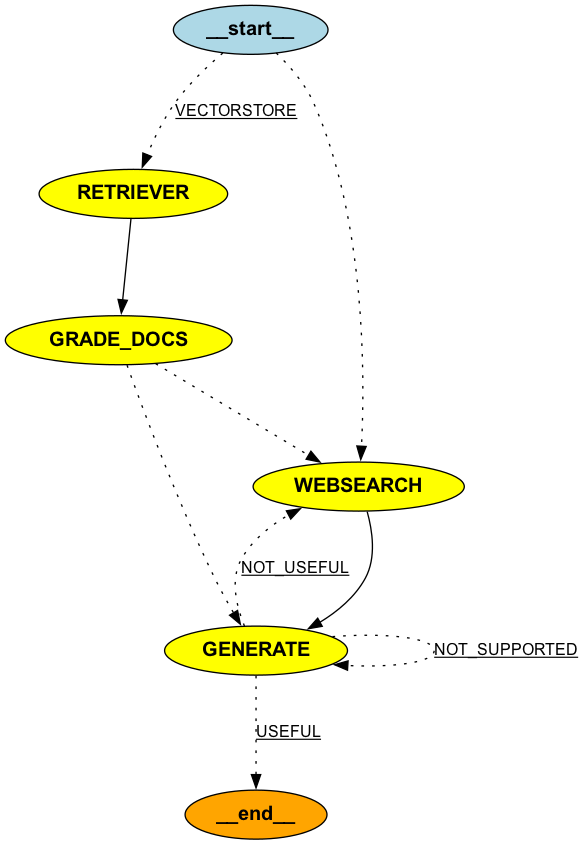
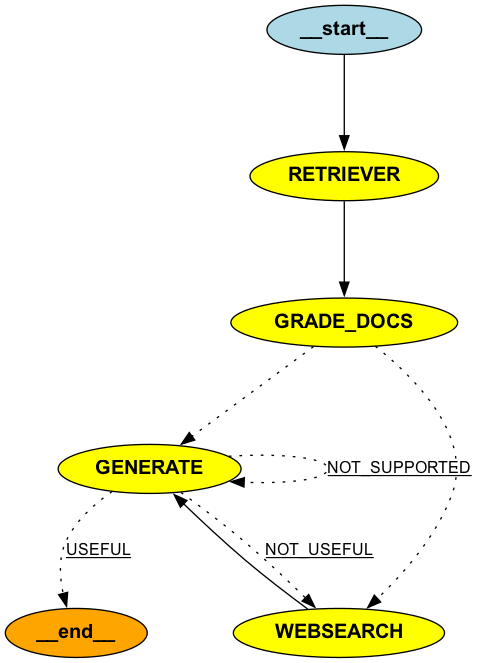
workflow = StateGraph(GraphState)
workflow.add_node(RETRIEVER, retriever_node)
workflow.add_node(GRADE_DOCS, grading_node)
workflow.add_node(GENERATE, generate_node)
workflow.add_node(WEBSEARCH, websearch_node)
workflow.set_entry_point(RETRIEVER)
workflow.add_edge(RETRIEVER, GRADE_DOCS)
workflow.add_conditional_edges(
GRADE_DOCS,
grade_conditional_node,
{
WEBSEARCH: WEBSEARCH,
GENERATE: GENERATE,
},
)
workflow.add_edge(WEBSEARCH, GENERATE)
workflow.add_edge(GENERATE, END)
workflow.add_conditional_edges(
GENERATE,
grade_generation_grounded_in_documents_and_question,
{NOT_SUPPORTED: GENERATE, NOT_USEFUL: WEBSEARCH, USEFUL: END},
)This graph structure allows for multiple paths and iterations, a key aspect of Self RAG. The system can re-attempt generation or seek more information based on its self-evaluation.
Self-Reflection: Document Grading
def grading_node(state: GraphState) -> Dict[str, Any]:
filter_docs = []
websearch = False
grade_template = ChatPromptTemplate.from_messages([
("system", system),
("human", "user question: {question}, retrieved document: {document}"),
])
grade = llm.with_structured_output(Grade)
template = grade_template | grade
for doc in documents:
result = template.invoke({"question": question, "document": doc.page_content})
if result.bool_score == "yes":
filter_docs.append(doc)
if len(filter_docs) < 2:
websearch = True
return {"question": question, "documents": filter_docs, "websearch": websearch}This function is reflected at the retrieval stage of the document. The system gives the relevance score to each document and determines whether it wants to fetch more information or not.
Self-Improvement: Generation Grading and Hallucination Detection
def grade_generation_grounded_in_documents_and_question(state: GraphState) -> str:
question = state["question"]
documents = state["documents"]
generation = state["generation"]
hallucination_result = hallucination_grader_prompt_chain.invoke(
input={"generation": generation, "documents": documents}
)
if hallucination_result.bool_score == "yes":
generation_answer_grader_result = generation_answer_grader_prompt_chain.invoke(
input={"generation": generation, "question": question}
)
if generation_answer_grader_result.bool_score == "yes":
return USEFUL
else:
return NOT_USEFUL
else:
return NOT_SUPPORTEDThis is the core part of the self-improving mechanism of Self RAG.
It reviews the generated response for:
1. For grounding in the given documents (it checks for the hallucination)
2. For the original question being posed
Based on this self-evaluation of the system, it can decide to:
1. Take the response as USEFUL
2. Attempt to generate another response as NOT_SUPPORTED
3. Present a web search to fetch further information on the same topic as NOT_USEFUL
Test Scenarios
To better understand how our Self RAG system behaves in various situations, let’s explore some test scenarios:
Scenario 1: Recent Event Query
Question: “What were the key outcomes of the 2024 UN Climate Change Conference?”
Expected Behavior: The local retriever might not have up-to-date information about this recent event. The document grader would likely determine that the retrieved documents are insufficient or outdated. This triggers a web search to fetch the latest information about the 2024 conference. The generator creates a response based on the web search results. The generation grader ensures the response is both relevant to the question and grounded in the retrieved information.If the response passes the grading, it’s returned to the user. If not, the system might attempt another generation or search iteration.
This scenario demonstrates Self RAG’s ability to recognize when it needs to seek current information and its capacity to integrate web search results into its response generation process.
Scenario 2: Technical Query with Sufficient Local Data
Question: “Explain the difference between String, StringBuffer, and StringBuilder in Java.”
Expected Behavior: The local retriever finds relevant documents explaining these Java classes. The document grader approves these documents as relevant and sufficient. The generator creates a response comparing the three classes. The generation grader checks if the response accurately explains the differences and is grounded in the retrieved information. If the response is satisfactory, it’s returned to the user. If not, the system might attempt to regenerate a more accurate or comprehensive explanation.
This scenario showcases Self RAG’s ability to leverage existing knowledge when sufficient information is available locally, while still applying self-evaluation to ensure the response meets quality standards.
Scenario 3: Ambiguous Query Requiring Clarification
Question: “Tell me about the effects of inflation.”
Expected Behavior: The local retriever finds general documents about inflation. The document grader approves these documents but flags that they might be too broad. The generator creates an initial response outlining general effects of inflation. The generation grader determines that the response, while accurate, might be too general. The system decides to seek clarification, generating a follow-up question like, “Would you like to know about the effects of inflation on a specific sector or time period?”. Based on the user’s clarification, the system would then repeat the process with a more focused query.
This scenario illustrates Self RAG’s ability to recognize when a query might be too broad and its capacity to engage in a clarifying dialogue to provide more targeted and useful information.
Scenario 4: Fact-Checking a Potentially Misleading Claim
Question: “Is it true that vaccines cause autism?”
Expected Behavior: The local retriever finds documents related to vaccines and autism. The document grader recognizes this as a sensitive topic and flags it for careful handling. The generator creates an initial response based on scientific consensus. The generation grader checks if the response is balanced, cites reputable sources, and addresses the misconception appropriately. If needed, the system might trigger a web search to find the most recent studies or statements from health organizations. The final response is carefully crafted to provide accurate information, explain the origin of the misconception, and point to authoritative sources.
This scenario demonstrates Self RAG’s ability to handle sensitive topics, fact-check claims, and provide responses that are not only accurate but also responsibly address potential misinformation.
Scenario 5: Multi-Step Problem Solving
Question: “How do I calculate the compound interest on a loan of $10,000 at 5% annual interest rate for 3 years, compounded monthly?”
Expected Behavior: The local retriever finds documents explaining compound interest and its calculation. The document grader approves these documents as relevant. The generator creates a step-by-step explanation of the calculation process. The generation grader checks if all steps are included and mathematically correct. If any step is missing or incorrect, the system regenerates that part of the explanation. The system might also decide to include a worked-out calculation with the exact figures provided in the question. The final response includes both the general formula explanation and the specific calculation for the given values.
This scenario showcases Self RAG’s ability to break down complex problems, provide step-by-step solutions, and self-correct if any part of the explanation is incomplete or inaccurate.
These test scenarios illustrate how Self RAG adapts its approach based on the nature of the query, the availability of information, and the quality of its initial responses. By continuously evaluating and refining its outputs, Self RAG can provide more accurate, relevant, and comprehensive responses across a wide range of query types.
Key Benefits of Self RAG
- High Precision Accuracy: Self-assessment of its generated output may reduce hallucinations and irrelevance.
- Adaptive Information Acquisition: The system will realize when it requires more information and head for acquiring the missing information.
- Iterative Enhancement: Responses can be improved through multiple generation attempts.
- Transparency: The self-evaluation process provides insight into the decisions that the system makes.
Conclusion
Moving toward more reliable and accurate AI systems, the self RAG is a crucial step. With mechanisms of self-reflection and self-improvement, we’re closer to the ultimate point in AI, critically evaluating the outputs and adapting approaches when necessary.
This implementation, built with LangGraph, constitutes one of the most impressive demonstrations of a flexible, modular design approach to the creation of sophisticated AI workflows. We continue to refine and build upon these concepts and are thus paving exciting paths for not just more accurate AI systems but also more transparent and trustworthy ones.
The road to more reliable AI is still on, and Self RAG is just one step in the right direction. It makes us question how AI can process information, but it also forces us to think about how it could question its own processes and improve on them.
Let’s Connect (Or Hire Me!)
The complete code for this Self RAG system is available in the GitHub repository. If you’re utterly enthralled with this blog or thinking “This person should definitely be on my team,” let’s connect! I’d love to chat about Agents, LLM gossip, or even exciting job opportunities.
Find me on LinkedIn and let’s dive deeper into the world of AI and LLMs together.